Refactoring legacy notebooks¶
This tutorial shows how to convert legacy notebooks into Ploomber pipelines.
Note
If you don’t have a sample notebook, download one from here.
or execute:
curl -O https://raw.githubusercontent.com/ploomber/soorgeon/main/examples/machine-learning/nb.ipynb
The only requirement for your notebook is to separate sections with H2 headings:
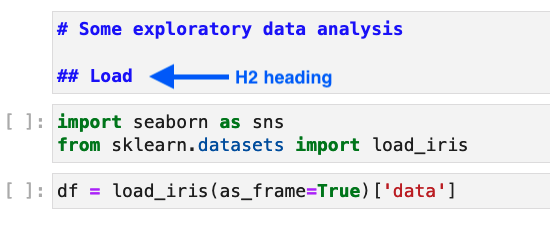
Here’s an example notebook with three sections separated by H2 headings:
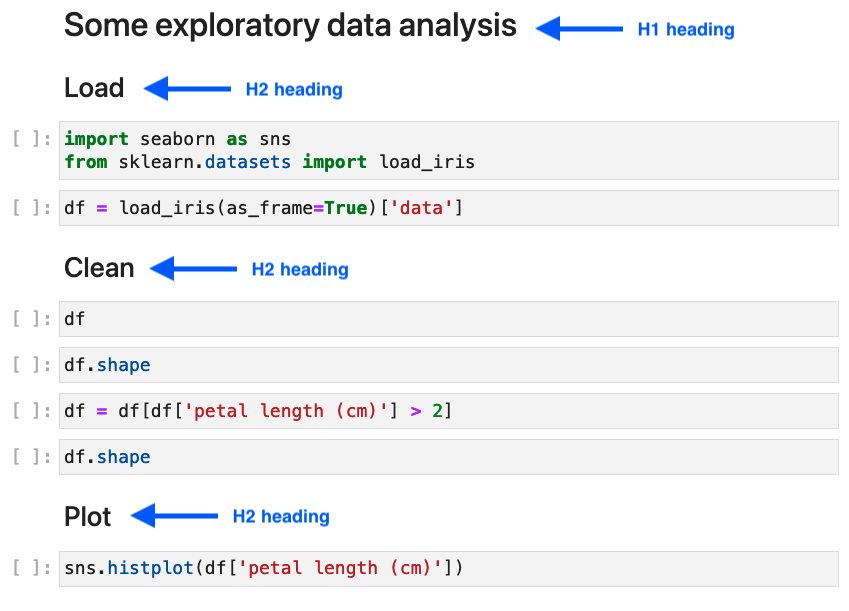
Once your notebook is ready, you can refactor it with:
# install soorgeon
pip install soorgeon
# refactor the nb.ipynb notebook
soorgeon refactor nb.ipynb
Tip
Sometimes, soorgeon may not be able to split your
notebook sections, if so, run soorgeon refactor nb.ipynb --single-task
to generate a pipeline with one task. If you have questions, send us a
message on Slack.
The command above will generate a pipeline.yaml with your pipeline
declaration and .ipynb tasks (one per section).
You can also tell Soorgeon to generate tasks in .py format:
# generate tasks in .py format (requires soorgeon>=0.0.13)
soorgeon refactor nb.ipynb --file-format py
Note that due to the Jupyter integration, you can open .py files as notebooks in Jupyter
To run the pipeline:
# install dependencies
pip install -r requirements.txt
# run Ploomber pipeline
ploomber build
That’s it! Now that you have a Ploomber pipeline, you can benefit from all our features! If you want to learn more about the framework, check out the basic concepts tutorial.