To run this locally, install Ploomber and execute: ploomber examples -n guides/intro-to-ploomber

Found an issue? Let us know.
Questions? Ask us on Slack.
Intro to Ploomber¶
Your first Python pipeline¶
Introductory tutorial to learn the basics of Ploomber.
Ploomber Tutorial Intro¶
We’ll forcast the relation between testing and active covid-19 cases.
We’ll see today how you can improve your work:¶
Run 100s of notebooks in parallel
Parameterize your workflows
Easily generate HTML/PDF reports
For a deeper dive, try the first-pipeline guide or the basic concepts overview. If YAML, Jupyter and notebooks sounds like a distant cousin, please check our basic concepts guide.
Parallelization¶
Ploomber creates a pipeline for you, so you can run independent tasks simultaneously.
It also cache the results so you don’t have to wait. You can drop the
force=True(last line) and rerun this cell.
In here we’ll train 4 different models simultaneously, and see it in a graph:
[1]:
from ploomber import DAG
from ploomber.tasks import ShellScript, PythonCallable
from ploomber.products import File
from ploomber.executors import Parallel
from ploomber.spec import DAGSpec
spec = DAGSpec('./pipeline.yaml')
dag = spec.to_dag()
# dag.executor = Parallel()
build = dag.build(force=True)
fatal: ref HEAD is not a symbolic ref
/home/prem/Documents/projects/ploomber/ploomberw/ploomber/src/ploomber/executors/serial.py:149: UserWarning:
=========================== DAG build with warnings ============================
- NotebookRunner: linear-regression -> MetaProduct({'nb': File('output/...ession.ipynb')}) -
- /home/prem/Documents/projects/ploomber/ploomber-projectsw/ploomber-projects/guides/intro-to-ploomber/tasks/linear-regression.py -
Output '/home/prem/Documents/projects/ploomber/ploomber-projectsw/ploomber-projects/guides/intro-to-ploomber/output/linear-regression.ipynb' is a notebook file. nbconvert_export_kwargs {'exclude_input': True} will be ignored since they only apply when exporting the notebook to other formats such as html. You may change the extension to apply the conversion parameters
=============================== Summary (1 task) ===============================
NotebookRunner: linear-regression -> MetaProduct({'nb': File('output/...ession.ipynb')})
=========================== DAG build with warnings ============================
warnings.warn(str(warnings_all))
[2]:
dag.plot()
[2]:
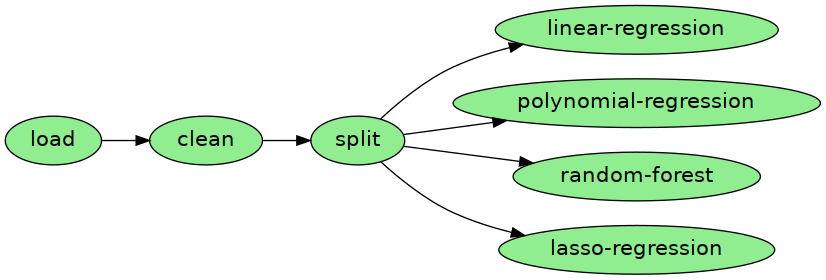
Parameterize workflows¶
In many cases, you’d run your analysis with different parameters/different data slices
Ploomber allows you to parametrize workflows easily
Here we’re training a linear regression with different parameters, using a notebook as template
[3]:
from ploomber.spec import DAGSpec
spec = DAGSpec('./pipeline-params.yaml')
dag = spec.to_dag()
build = dag.build(force=True)
build
dag.plot()
fatal: ref HEAD is not a symbolic ref
[3]:

Caching optimization¶
Note that the previous table has load ran as fail?
This task ran in a previous pipeline so there’s no point of reruning it. (we can force it to run if needed).
In the next table, all of the pipeline results were cached so we can focus on code that changed only, saving hours of compute time.
[4]:
build = dag.build()
build
[4]:
| name | Ran? | Elapsed (s) | Percentage |
|---|---|---|---|
| load | False | 0 | 0 |
| clean | False | 0 | 0 |
| split | False | 0 | 0 |
| linear-regression-0 | False | 0 | 0 |
| linear-regression-1 | False | 0 | 0 |
Automated reports¶
In case we have a dataset to track/a stakeholder report, we can generate it as part of our workflow. We created the report as part of our first cell pipeline build, so we can consume it immediately. Let’s load our stakeholder report from our previous linear regression task:
[5]:
# open each specific html report/data if exist
from IPython.display import IFrame, display
from pathlib import Path
report = "./output/linear-regression.html"
if Path(report).is_file():
display(IFrame(src=report, width='100%', height='500px'))
else:
print("Report doesn't exist - please run the notebook sequentially")
Report doesn't exist - please run the notebook sequentially
Interactive reporting¶
Compare your previous experiments interactively
[6]:
from sklearn_evaluation import NotebookCollection
# ids to identify each experiment
ids = [
'linear-regression', 'polynomial-regression', 'random-forest', 'lasso-regression'
]
# output files
files = [f'output/{i}.ipynb' for i in ids]
nbs = NotebookCollection(paths=files, ids=ids)
list(nbs)
nbs['plot']
[6]:




Where to go from here¶
Use cases¶
Community support¶
Have questions? Ask us anything on Slack.
Resources¶
Bring your own code! Check out the tutorial to migrate your code to Ploomber.
Want to dig deeper into Ploomber’s core concepts? Check out the basic concepts tutorial.
Want to start a new project quickly? Check out how to get examples.